
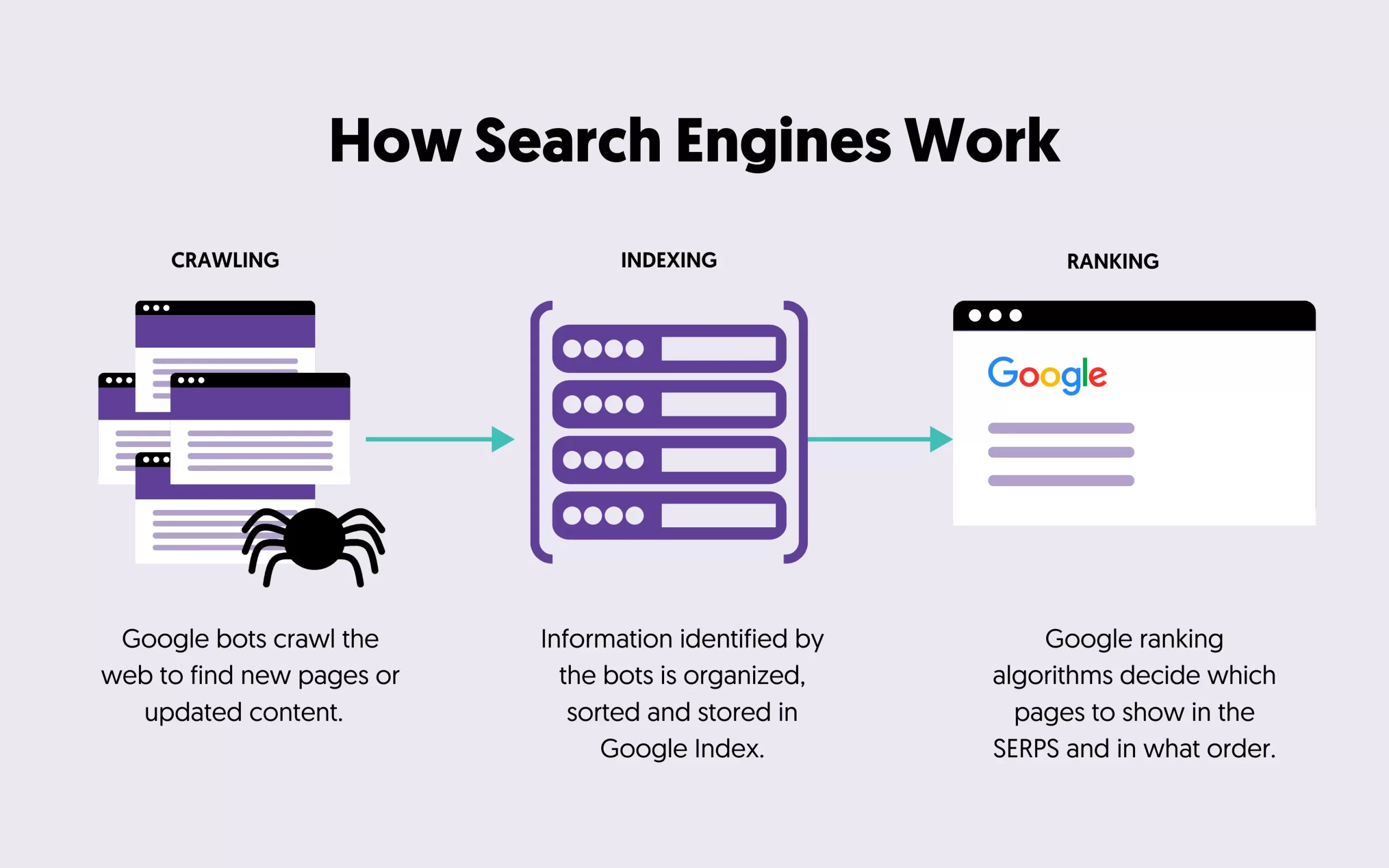
Exploring the intricate world of search engines unveils a fascinating process. Web crawlers, often referred to as spiders or bots, meticulously traverse the vast web landscape, diligently following links to discover new pages. These unearthed pages find a home in an index, serving as the foundational database from which search engines draw results.
For those immersed in the realm of SEO, comprehending the inner workings of search engines is paramount. It’s akin to deciphering a complex puzzle – optimizing for search engines becomes a challenging task without a clear understanding of their mechanisms.
In this guide, we delve into the mechanics of search engines, unraveling the mysteries that underpin effective SEO strategies. If you have specific inquiries or areas you’d like to explore further in the realm of SEO, feel free to share, and I’ll provide insights tailored to your needs.
A. Url Discovery:
1. The first stage is finding out what pages exist on the web. There isn’t a central registry of all web pages, so Google must constantly look for new and updated pages and add them to its list of known pages. This process is called “URL discovery”.
2. Some pages are known because Google has already visited them. Other pages are discovered when Google follows a link from a known page to a new page.
B. Crawling:
- Once Google discovers a page’s URL, it may visit (or “crawl”) the page to find out what’s on it. We use a huge set of computers to crawl billions of pages on the web. The program that does the fetching is called Googlebot.
- Googlebot uses an algorithmic process to determine which sites to crawl, how often, and how many pages to fetch from each site.
C. Rendering:
- During the crawl, Google renders the page and runs any JavaScript it finds using a recent version of Chrome, similar to how your browser renders pages you visit. Rendering is important because websites often rely on JavaScript to bring content to the page, and without rendering Google might not see that content.
D. Indexing:
- After a page is crawled, Google tries to understand what the page is about. This stage is called indexing and it includes processing and analyzing the textual content and key content tags and attributes, such as title elements and alt attributes, images, videos, and more.
- During the indexing process, Google determines if a page is a duplicate of another page on the internet or canonical. The canonical is the page that may be shown in search results. To select the canonical, we first group together (also known as clustering) the pages that we found on the internet that have similar content, and then we select the one that’s most representative of the group.
E. Serving search results:
- When a user enters a query, our machines search the index for matching pages and return the results we believe are the highest quality and most relevant to the user’s query. Relevancy is determined by hundreds of factors, which could include information such as the user’s location, language, and devices.